1 overview
leveldb是基于LSM-Tree的单机存储引擎。如下图是leveldb数据的组织方式,包括两个部分
- 在内存中包括两个支持查找和插入的数据结构,其中一个是可写的(mutable memory table),另外一个是只读的(immutable memory table),当mutable memory table占用内存达到配置值时,会转换为immutable memory table。
- 在磁盘中,数据是分层存储的,每一层包括多个文件,leveldb称之为table,每个文件都按序保存多个KV对,除了第0层,其他每一层的table都不重叠,这意味着每个table存储的key都是不一样的。

leveldb的key包括三个部分:user key、sequence number和type。sequence number用于snapshot,type是删除标记。leveldb是按照user key来排序,如果user key相同,那么按照sequence number降序排序,因此(hello,1)是小于(hello,0)的。下面我们称这个格式的key为internal key以和user key区分。
由于intenal key包含type,因此插入和删除就是同一个逻辑了,只是type不同。对于每个更新,leveldb都会分配一个自增的sequence number,这样从leveldb的视角来看,即使用户多次写入同一个user key,但是由于sequence number不一样,因此internal key也不同。
leveldb的更新会追加到mutable memory table中,一旦mutable memory table占用内存达到配置的阈值,mutable memory table就会转换为immutable memory table,启动后台任务将immutable memory table写入到第0层中。对于查找操作,leveldb会先从memory table中查找,如果没有找到,就会依次从第0层往更高层进行查找,直到查找到或者所有层都查找完。更新时采用追加写的方式,可以在较低的复杂度下完成,而对于查找,如果memory table不存在该key,就需要从第0层开始查找,由于第0层是可能包含重叠的,最坏情况下需要遍历整个第0层的table文件才能确定是否存在,因此leveldb引入另外一个机制(compaction)来提高查找的效率。
2 table
leveldb每层包括多个文件,leveldb称之为table,每个table对应持久化存储下的一个文件。table是一个sorted map,这意味着table的数据是有序的。我们先看下table的数据组织,如下图,

DataBlock:table的有效负载,存储按照key排序的多个KV对FilterBlock:过滤器,在查询时用于检查key是否存在MetaIndexBlock:记录过滤器的策略以及FilterBlock的位置IndexBlock:记录每个DataBlock的位置信息以及对应的最大keyFooter:固定大小,记录IndexBlock和MetaIndexBlock的位置信息
2.1 DataBlock
table有效负载为DataBlock,每个DataBlock默认大小为4k,包含多个有序的KV对。DataBlock采用前缀压缩的方式来存储KV,使用前缀压缩能够有效减少需要的存储空间。如下图,现在插入两条记录hello_0和hello_1,由于hello_1和hello_0有共同前缀hello_,因此hello_1的key实际只会存储一个字节。

使用前缀压缩的方式来存储KV有个弊端就是查找变得很低效,尽管有IndexBlock能够定位可能存在的DataBlock了,但是需要顺序遍历完整的DataBlock才能够完成查找。DataBlock的数据是有序的,理论上可以在对数级别的时间复杂度下完成查找,但是由于采用了前缀压缩只有顺序遍历才能确定key的实际数据,因此无法使用二分查找的方式。leveldb使用重启点的技术来兼顾查找和存储的效率,每个重启点存储固定数量的KV,这些KV使用迁回压缩方式存储,因此每个重启点的第一个KV的key都是没有经过压缩的、完整的数据,那么在查找时只需要二分查找重启点后再线性遍历该重启点下所有的KV。DataBlock在磁盘的数据组织方式如下图,该DataBlock包含两个重启点。

2.2 FilterBlock
FilterBlock是过滤器,在查询时可以先通过过滤器过滤掉一定不存在的key,这样做的好处是可以避免读放大。尽管FilterBlock在每个table中只有一个,但是每个DataBlock都有私有的过滤器数据存储在FilterBlock中,私有的过滤器数据可以提高准确率。如下图,FilterBlock的数据包含三部分,
- filter:用于过滤的数据
- off:每个filter的位置
- base:任意给定
offset,通过base来确定filter的位置

目前leveldb的base默认为11,这意味着每2kb的数据将会产生一个filter,这里有个问题
前文描述DataBlock的默认大小为4k,那么将会产生两个filter,这不是和每个DataBlock都有一个filter违背吗?
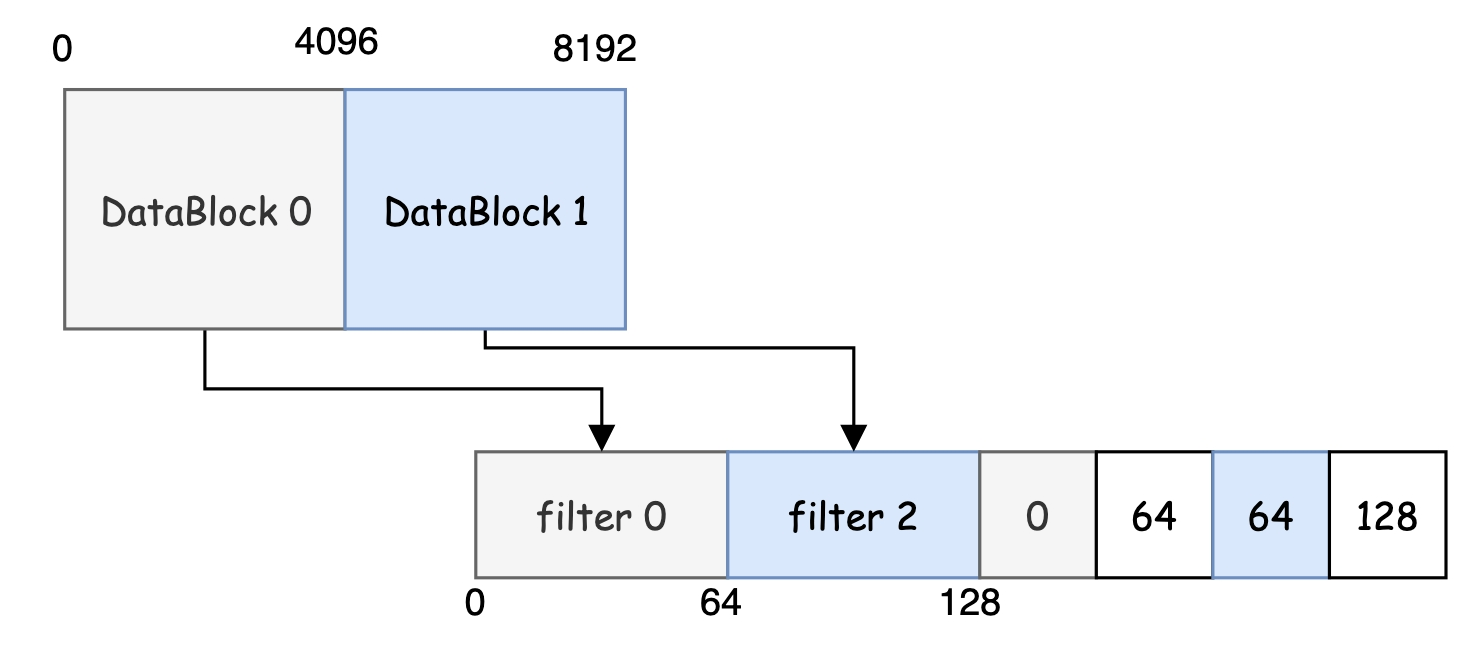
其实不是的,我们在查询时,首先通过IndexBlock确定了key可能存在的DataBlock,也就是意味着拿到了DataBlock在table文件的offset,通过这个offset >> base确定filter的位置,这样只会拿到一个filter。通过一个实际的例子来理解这句话,如下图,包含两个DataBlock,分别在文件的第一个4k和第2个4k,FilterBlock总共包含两个filter,但是位置信息包括四个。假设我们现在查询的key通过IndexBlock确定在DataBlock 1中,该DataBlock 1的位置为4096,通过4096 >> 11得到filter的索引为2(索引从0开始),因此确定filter在[64, 128)。
2.3 MetaIndexBlock
MetaIndexBlock包含table的元数据,目前MetaIndexBlock只有一条数据:FilterBlock的过滤器策略以及FilterBlock的位置信息。table的元数据部分是在初始化table时就会读取加载到内存中,而数据部分按需加载的,这也是MetaIndexBlock存在的原因,在table中抽象一层元数据部分,让代码结构更加清晰。
2.4 IndexBlock
IndexBlock是一个索引,在查找时用于确定待查找的key所在的DataBlock。IndexBlock包括多个KV,只不过这里的value是DataBlock的位置信息,如下图,每个DataBlock在IndexBlock都有一个KV,其中key是该DataBlock最大的key,value是DataBlock的位置信息。

3 snapshot
snapshot是db在某个时间点的快照,在snapshot没有释放时,需要保证snapshot时间点之前的数据一直存在。leveldb的snapshot依赖internal key的sequence number实现的。查找时可以指明当前查找的snapshot,那么leveldb会查找小于该snapshot包含的sequence number范围的数据。
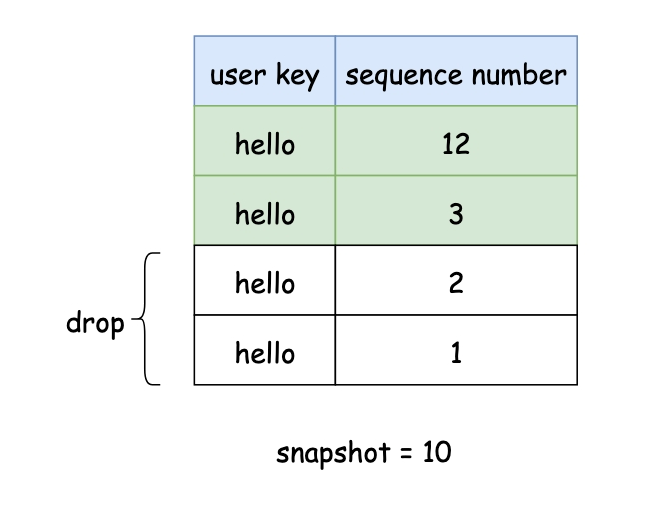
internal key包含sequence number,每次执行更新操作时,都会分配一个自增的sequence number。leveldb的排序先按照user key从小到大排序,如果user key相等,那么按照sequence number从大到小排序,这样的话,对于某一个user key最新的操作总是最先出现。compaction是将某一层的table文件和下一层有重叠的table文件执行归并操作,对于同一个user key的数据只会保留一份。由于有了snapshot,就要重新审视下compaction的逻辑了,compaction时需要兼顾已存在的snapshot,保证不会丢弃snapshot之前的数据。如下图,有一个sequence number为10的snapshot,db中总共存在四个相同user key的数据,对于第一次出现(sequence number=12)的数据会保留,同时也会保留一份snapshot之前的数据(sequence number=3),其他全部丢弃(sequence number=1或者=2)。
4 compaction
在前文,我们描述过leveldb的更新是追加写入mutable memory table,当mutable memory table写满后,会构造一个空的mutable memory table,而老的mutable memory table会转换为immutable memory table,并且启动后台任务将immutable memory table写到磁盘以table文件形式存在。追加写的好处是更新非常快,最好的情况下只需要在内存中的数据结构执行一次更新,最坏情况下也只有一次固定大小的磁盘写入的开销加一次mutable memory table的更新操作。但追加写对于读操作来说是非常不友好的,如果memoey table存在查找的key,那么最多只需要两次memory table的查找操作,但是如果不存在,最坏情况下需要读取所有第0层的table文件。假如读取的数据大小为1k,第0层包含4个table文件,IndexBlock大小为4k,DataBlock大小为4k,那么最多需要读取$4 \times 4k + 4 \times 4k =32k$的数据,读放大为32,并且读放大随着第0层table文件数量线性增长。为了避免第0层table文件数量的无限增长,leveldb使用compaction将第0层的table文件进行归并,形成一个或者多个第1层的文件,在归并过程中,对于标记为删除的数据或者同一个user key的旧数据都丢弃,避免磁盘空间的浪费。compaction包括两方面
- 将immutable memory table持久化写入到磁盘以table形式存在
- 将某一层的一个或者多个table文件和下一层具有重叠区域的table文件进行归并
4.1 memory table compaction
immutable memory table持久化写入到磁盘是很简单的操作,也就是将内存的有序数据结构序列化到磁盘中。需要注意的是,leveldb对于新生成的table文件做了个优化,在特定情况下会放到第1层或者第2层,而不是直接放到第0层。
- 如果和第0层有重叠或者第1层有重叠,那么放到第0层
- 如果和第1层或者第2层没有重叠,并且和第2层或者第3层重叠的table文件数量小于10个,那么放到第1层或者第2层
如下图,新的table文件范围为[f,k],由于和第0层以及第1层都没有重叠,并且和第2层重叠的table文件数量小于10个(1个),因此将新的table文件放到第1层。

如果和第0层有重叠,放到第0层很容易理解,如果不放在第0层,由于新的table文件总是包含最新的数据,读操作是从第0层开始查找的,只要找到就返回,那么由于新的table文件不在第0层会导致读到旧数据。而和第一层有重叠,由于第1层到第6层,所有table文件不能重叠,因此只能放到第0层。这个优化的逻辑是什么呢,尝试回答三个问题来解答该问题。
- 为什么和第0层以及第1层没有重叠,并且和第2层重叠的table文件数量小于10个就放到第1层呢?对于磁盘的table文件的compaction,简单来说就是从第$i$层寻找一个或者多个table文件和第$i+1$层有重叠的table文件执行归并操作,生成新的table文件放到第$i+1$层。对于第$i$层($i \gt 0$)的compaction,只会选择一个文件执行compaction,而对于第0层,选择一个table文件后,需要把和该table文件具有重叠的文件都选中一起compaction,这势必会带来更多的磁盘IO,因此第0层的compaction是较为昂贵的操作。因此将新的table文件尝试放到第1层或者第2层,会避免昂贵的第0层的compaction。
- 为什么要求和祖父层重叠的table文件数量小于10个?如果重叠的table文件太多,那么后续对该层执行compaction并且选择的table文件就是这个新生成的table文件,由于祖父层太多table文件和该文件重叠,就会导致compaction的文件数量过多引起较多的磁盘IO。
- 为什么不尝试往大于2的层放置新的table文件?如果新的table文件包含后续不会插入的key,那么如果放到太高的层,会导致读变得很低效。
4.2 table compaction
leveldb有自己的策略来选择哪一层哪个table文件作为compaction的源,暂且不考虑leveldb是如何选择table文件的,我们先深入看下table文件的compaction的过程。
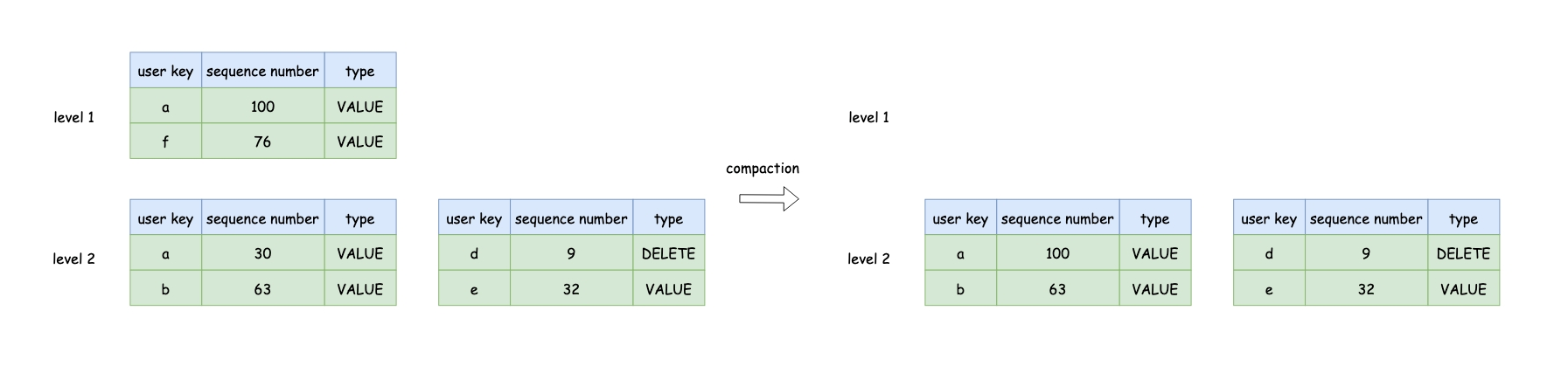
首先leveldb按照某些策略,选择某一层中的某一文件,如果是第0层,会将所有和该文件重叠的文件都选中,接下来根据选中的文件,接确定下一层和选中文件重叠的table文件,最后对这些table文件执行多路归并操作生成新的table文件即可。
在多路归并的过程中,有两点需要注意:
- 保证已有的快照需要的KV不会丢弃
- 对于删除标记的KV,如果该条KV是整个db唯一的一条,那么可以把这条KV给丢弃,如果对于删除标记的KV直接丢弃,更高层可能存在同样的user key,compaction后导致删除的KV还存在
第一点,在snapshot那节我们描述过,对于第二点,这里举个例子,在较早时我们插入一条user key为hello的KV,并且该KV所在的table文件已经在较高的层,假设在第5层,现在我们删除user key为hello,并且有删除标记的table文件在第1层,该table文件正在执行compaction,如果直接删除该条带有删除标记的KV,那么compaction后查找user key为hello时,会从第5层的table文件中找到。

在归并过程中,有两个条件会触发将以归并的数据生成新的table文件,其中第2点是leveldb做的优化,能够保证未来compaction的效率,避免compaction占用太多磁盘IO。
- 已经归并的数据已经达到配置的大小
- 归并的数据和第$i+2$层重叠的table文件已经超过10个
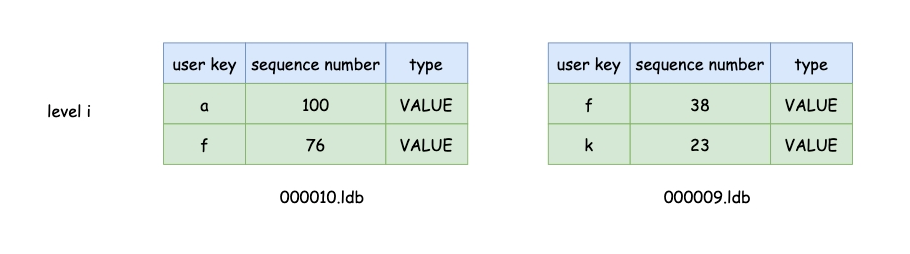
compaction还有个细节很重要,如下图,我们要对第$i$层的000010.ldb执行compaction,由于同一层的000009.ldb包含user key为f的数据,因此要把000009.ldb也一起compaction,否则compaction后,user key为f较新的数据下沉到第$i+1$层,之后尝试读取user key为f的数据将会读到000009.ldb包含的老数据。
4.3 table compaction策略
leveldb选择哪一层哪一个table文件有两个策略:
- 每一层的数据规模
- 某个table文件的无效查找次数
leveldb会为每一层的数据规模进行打分,分值最高的并且分值超过1会优先进行compaction的层。对于第0层,是根据文件数量进行打分,超过4个后分值就开始超过1;对于其他层,是根据文件总大小打分,第1层为10m,第2层为100m,依次按照10的倍数递增。
leveldb在查找或者读取db时,会记录table文件查找且没有命中的次数,没有命中相当于浪费IO,那么无效查找相当的磁盘IO量超过该对该table文件执行compaction所需要的磁盘IO量,那么执行compaction带来的收益会更大。leveldb给了一个例子:
假设从某个table文件查找一次耗时10ms,读写磁盘1mb也耗时10ms,对1mb的数据执行compaction需要的磁盘IO为25mb:下一层分别读取和写入10-12mb(compaction保证新生成的table执行compaction时下一层文件不会超过10个,由于两侧可能相邻,因此比例在1:10到1:12之间)以及读取当前层的1mb。这意味着1次compaction的代价相当于25次查找,因此如果无效查找次数过多,可以对该文件执行compaction避免未来更多的无效查找导致磁盘IO的浪费。
leveldb会优先以第一条策略为标准,只有当分值小于1时才会执行第2条策略。在执行第一条策略时,选择的table文件很讲究,leveldb会记录该层上一次执行compaction的位置,当该层再次发生compaction时,会选择上一次位置之后table文件。
5 consistency
leveldb提供了快照读的一致性模型,并且读写以及读和compaction都可以并行执行。对于读写并行执行,由于每次写都会分配一个自增的sequence number,因此只要在读的时间点明确该时间点的sequence number就能够实现快照读的一致性。而对于后者,在执行compaction引发的归并操作会删除某一层的table文件,如果删除的table文件是某个读取操作需要的,会破坏一致性模型。leveldb增加一个version的概念,每个version包括version生成时所有table文件的引用。正常情况下,只会有一个version,即current version,当compaction结束会新增version,表明table文件发生变动,并且释放原来老的current version的引用。leveldb在执行读操作时,会对current version新增引用,compaction结束在执行删除文件时会避免已有version引用的文件,这样读操作没有结束,version就会一直存在,其引用的table文件也会一直存在,保证了快照读的一致性语义。
6 recovery
在第一节的图中有磁盘有额外两个文件:write-ahead log(WAL)和manifest,这两个文件是用于恢复db的。leveldb的memory table在系统crash后就会丢失,如果没有其他机制存在就会导致数据丢失,WAL是一种常用的机制避免数据丢失的机制。在对db执行更新操作之前,首先会写入WAL后,写入成功后才会实际执行db的更新操作,在机器宕机后,可以通过WAL恢复当前之前写入的数据。
其次,compaction在执行期间,如果系统宕机会产生垃圾数据,leveldb每次执行完compaction后都会产生一个version edit,version edit包括删除的table文件列表和新创建的table文件列表。version edit相当于diff,我们还得有一个基线,通过基线加diff的方式leveldb就能够恢复。leveldb对于每个文件,不管是table、WAL还是manifest,都共享同一个自增的ID生成器,基线只需要记录下该ID生产器当前值即可。